앞선 글에서 살펴본 시계열 데이터는 동분산성, 자기상관성, 정상성 등 데이터 통계의 가장 기본적인 가정을 깨는 고유한 데이터임을 알 수 있다. 이 데이터의 경우 기존 머신러닝 기법인 ARIMA 계열에 데이터를 통합하기 어려우므로 이 데이터의 특이성을 제거한 후 머신러닝에 삽입해야 한다. 이 시간은 다음과 같습니다
1. 차별화
데이터를 차별화하는 것은 시간 t와 시간 t-1의 값 사이의 차이를 찾는 것으로 구성됩니다.
간단히 말해서, 데이터를 차별화하면 데이터의 가변성 값을 알 수 있고, 전후 데이터의 영향을 제거할 수 있으며, 임의의 데이터만을 사용하여 기계 학습 예측을 할 수 있습니다.
![[프로젝트 링]3주차-3) 데이터센터 수요 급증…건설사 '사업개발자' 참여 러시](https://most.eternals.kr/wp-content/plugins/contextual-related-posts/default.png "[프로젝트 링]3주차-3) 데이터센터 수요 급증…건설사 '사업개발자' 참여 러시")
 2024년 비즈니스를 성장시킬 9가지 전자상거래 트렌드")

그 차이를 수학 공식으로 표현하면 다음과 같습니다.

이때 차이 데이터의 첫 번째 값에서 빼야 할 이전 값이 없으므로 변화 값을 얻을 수 없다. 따라서 데이터를 미분하면 결과적으로 t-1개의 데이터 항목을 얻을 수 있다.
다음은 Google의 주가 데이터입니다. 왼쪽은 차이 전의 데이터(트렌드가 있기 때문에 고정적이라고 말하기는 어렵습니다)이고 오른쪽은 차이 후의 데이터입니다.
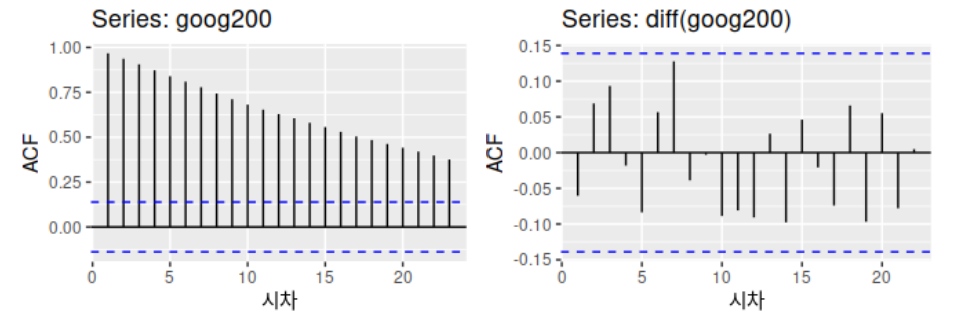
차이 이후의 데이터는 지난 장에서 논의한 백색 잡음 데이터 유형으로 완전히 변환됩니다. 이러한 방식으로 우리는 차이에 의한 완전히 무작위적인 변동으로 데이터를 추출할 수 있습니다. (데이터가 이전 데이터와 상관관계가 없다고 가정하면 분석 가능)
*때로는 하나의 차이가 아직 고정되지 않았기 때문에 두세 개의 차이가 사용됩니다.
2. 로그 변환
로그 변환은 시계열 데이터뿐만 아니라 데이터의 변동성이 너무 커서 분석이 어려운 데이터에도 적용되는 경우가 많습니다. 이 방법은 특히 데이터의 분산이 클 때 고려할 수 있으며, 이는 데이터의 전체 범위를 줄이는 원리이다. 다음 포스팅을 참고하여 사진과 함께 알아보도록 하겠습니다.
https://datasciencefromsebi.12
데이터 분석 시 로그 유지(세상에서 가장 간단한 설명)
우리는 때때로 이상한 데이터를 접하게 됩니다… (하지만 실제로는 자주). 예를 들어 데이터는 다음과 같을 수 있습니다…? 아니면 이럴까요………….? 참으로 기이한 현상이 아닐 수 없습니다. 이것은 나의
datasciencefromsebi.tistory.com
3. 로그 변환 + 차이
대부분의 경우 로그 변환은 데이터 전처리에서 먼저 수행됩니다. 대수 변환으로 분산을 안정화시킨 후, 그 차이에 의해 데이터가 정상이 되도록 변경됩니다. 관련 예로, 시계열이 아닌 데이터를 전처리할 때 로그 변환 후 스케일러를 적용하는 일반적인 방법을 기억하면 이해하기 쉽습니다.
4. 내 데이터는 정상입니다
이렇게 변환된 내 데이터는 (마침내) 기계 학습으로 전환할 수 있는 정규성을 갖습니다. 이를 확인하는 방법은 보통 2가지가 있는데, 하나는 차트의 모양을 확인하여 육안으로 확인하는 것이고, 하나는 수치로 확인하는 것입니다.
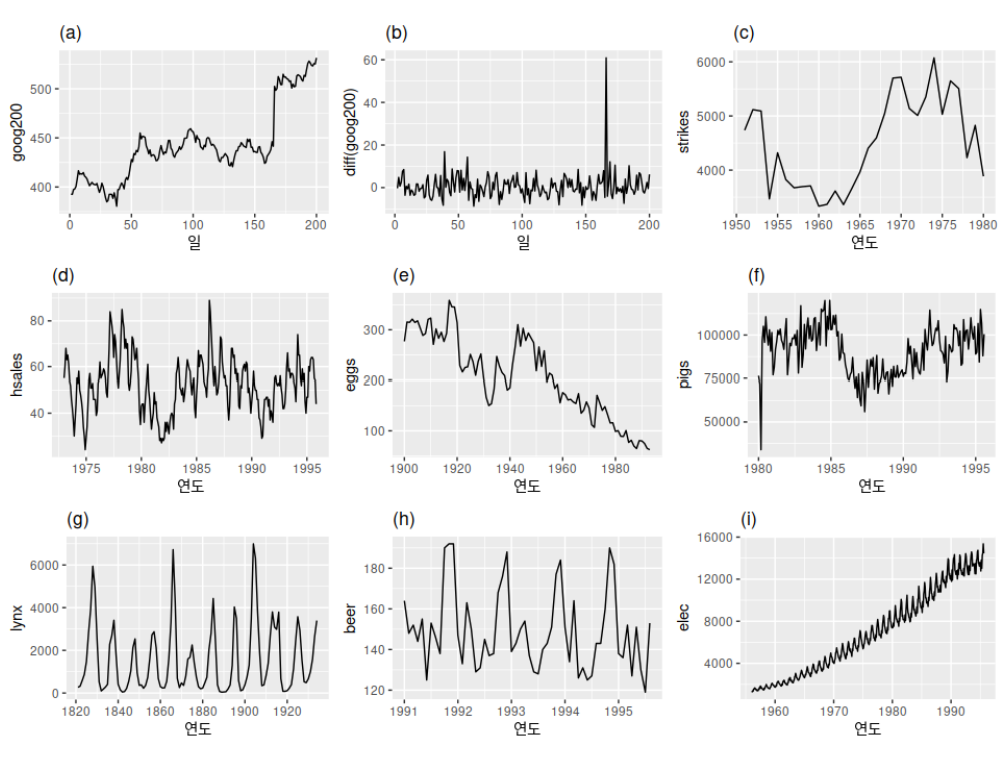
먼저 “눈으로 보는 방법”에 앞서 방법을 설명하겠습니다. 이전 게시물의 이 표에서는 b와 g만 고정 데이터로 표시했습니다. 그래프를 시각화하여 추세, 계절성 등이 제거되었는지, 분산이 얼마나 넓은지 쉽게 확인할 수 있습니다.
다음으로 두 번째 방법인 숫자 확인 방법에 대해 설명하겠습니다.
1, 자기상관 함수 (ACF; Autocorrelation Function): 차이 값이 ACF 범위 내에 있으면 데이터가 고정된 것으로 간주할 수 있습니다.
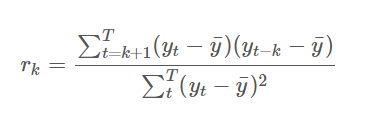
이 복잡한 공식을 이해할 필요는 없지만 시각화할 때 신뢰 구간에 속하는지 시각적으로 확인하기만 하면 됩니다. 이에 대해서는 추후 포스팅에서 자세히 다루도록 하겠습니다.
2. 디키 풀러 테스트
다음은 시계열 데이터가 안정적이지 않다는 귀무가설에서 p-값이 0.05를 초과할 때 사용하는 일반적인 방법입니다.
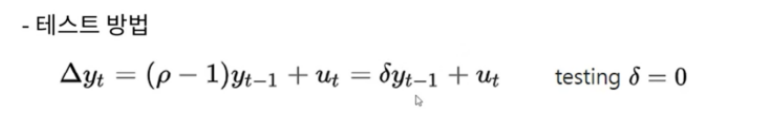
다음 장에서는 다양한 시계열 모델에 대한 개요를 제공합니다.